دمج الذكاء الاصطناعي والتداول: كيفية إجراء تداول تلقائي للعملات المشفرة باستخدام التعلم الآلي في عام 2026
دليل عملي حول دمج الذكاء الاصطناعي والتداول: كيفية إجراء تداول تلقائي للعملات المشفرة باستخدام التعلم الآلي في عام 2026 مع نقاط فحص أساسية ومخاطر وأدوات مرتبطة لاتخاذ قرار أفضل.
لقد حان عصر تداول الذكاء الاصطناعي
حتى أوائل العقد 2020، كان التداول الخوارزمي مقتصرًا على صناديق الكوانت في وول ستريت. كان يتطلب نماذج رياضية معقدة، بنية تحتية متخصصة، ورأس مال أولي بملايين الوون.
في عام 2026، تغيرت ثلاثة أشياء.
أولاً، مع نضوج بايثون ومكتبات التعلم الآلي مفتوحة المصدر (scikit-learn، PyTorch، TensorFlow)، أصبحت تنفيذ النماذج المعقدة شائعة.
ثانيًا، مع فتح واجهات برمجة التطبيقات (API) للبورصات، أصبح بإمكان الأفراد التداول بنفس البيانات وسرعة التنفيذ.
ثالثًا، ساعدت مساعدات الذكاء الاصطناعي (Claude، ChatGPT) في كتابة أكواد التداول المعقدة.
في هذه المقالة، سنشرح كيف نبني نظام تداول ذكاء اصطناعي يتعلم ويتكيف فعليًا يتجاوز روبوت RSI البسيط.
الفرق بين التداول الخوارزمي التقليدي وتداول الذكاء الاصطناعي
التداول الخوارزمي التقليدي
قائم على القواعد (Rule-Based):
IF RSI < 30 → شراء
IF RSI > 70 → بيع
المزايا: بسيط، قابل للتفسير، قابل للتنبؤ
العيوب: غير قادر على التكيف مع تغيرات السوق، يلتقط أنماطًا بسيطة فقطتداول الذكاء الاصطناعي / التعلم الآلي
قائم على البيانات (Data-Driven):
الإدخال: السعر، حجم التداول، المؤشرات الفنية، مشاعر الأخبار، بيانات السلسلة
النموذج: تعلم الأنماط المخفية من عشرات إلى آلاف المتغيرات
الإخراج: احتمالات الشراء/البيع/الاحتفاظ والعائد المتوقع
المزايا: التقاط الأنماط المعقدة، بعض القدرة على التكيف مع تغيرات السوق
العيوب: صندوق أسود، خطر الإفراط في التخصيص، الحاجة إلى بيانات كثيرةثلاث تقنيات تداول ذكاء اصطناعي مستخدمة في الواقع
1. توقع السلاسل الزمنية (Time Series Forecasting)
طريقة تستخدم الشبكات العصبية المتكررة (RNN) مثل LSTM (ذاكرة قصيرة وطويلة الأمد) لتوقع اتجاه الأسعار المستقبلية.
- الإدخال: بيانات OHLCV (سعر الافتتاح، أعلى سعر، أدنى سعر، سعر الإغلاق، حجم التداول) لآخر 60 يومًا
- الإخراج: اتجاه السعر في الأربع ساعات القادمة (احتمالية الارتفاع/الانخفاض)
- الدقة: من 56% إلى 62% وفقًا لنموذج LSTM المعدل جيدًا (مقارنة بـ 50% عشوائيًا)
2. تداول قائم على تحليل المشاعر (Sentiment Analysis)
يتفاعل سوق العملات المشفرة بشكل خاص مع الأخبار ووسائل التواصل الاجتماعي. نستخدم نموذج معالجة اللغة الطبيعية (NLP) لقياس مشاعر السوق واستخدامها كإشارات تداول.
- مصادر البيانات: Twitter/X، Reddit، مجتمعات العملات المحلية، عناوين الأخبار
- النموذج: مصنف مشاعر مالية قائم على BERT (إيجابي/سلبي/محايد)
- الاستخدام: إشارات دخول/خروج عندما تتغير درجة المشاعر بشكل حاد
3. التعلم المعزز (Reinforcement Learning)
طريقة يتعلم فيها الوكيل الاستراتيجيات المثلى من خلال التجربة المباشرة في بيئة التداول. تشبه المبادئ المستخدمة في ذكاء الألعاب (مثل AlphaGo).
- الوكيل: ذكاء اصطناعي يختار الشراء/البيع/الاحتفاظ
- البيئة: محاكاة بيانات الأسعار التاريخية
- المكافأة: العائد + نسبة شارب - تكاليف التداول
- التعلم: اكتشاف الاستراتيجية المثلى من خلال ملايين المحاكاة
تنفيذ روبوت تداول التعلم الآلي باستخدام بايثون
إعداد البيئة
pip install pandas numpy scikit-learn xgboost ta ccxt matplotlibهندسة الميزات: تحويل البيانات الخام إلى مدخلات التعلم الآلي
import pandas as pd
import numpy as np
from ta import add_all_ta_features
def create_features(df: pd.DataFrame) -> pd.DataFrame:
"""إنشاء ميزات التعلم الآلي من بيانات OHLCV"""
# مؤشرات فنية أساسية (باستخدام مكتبة ta)
df = add_all_ta_features(
df, open="open", high="high", low="low",
close="close", volume="volume", fillna=True
)
# ميزات معدل التغير في السعر
for period in [1, 3, 7, 14, 30]:
df[f'return_{period}d'] = df['close'].pct_change(period)
# ميزات التقلب
df['volatility_7d'] = df['close'].pct_change().rolling(7).std()
df['volatility_30d'] = df['close'].pct_change().rolling(30).std()
# اكتشاف حجم التداول غير الطبيعي
df['volume_ratio'] = df['volume'] / df['volume'].rolling(20).mean()
# المتغير المستهدف: إذا ارتفع السعر بعد 4 ساعات بنسبة 1% أو أكثر، يكون 1، وإلا 0
df['target'] = (df['close'].shift(-4) > df['close'] * 1.01).astype(int)
return df.dropna()تدريب نموذج XGBoost
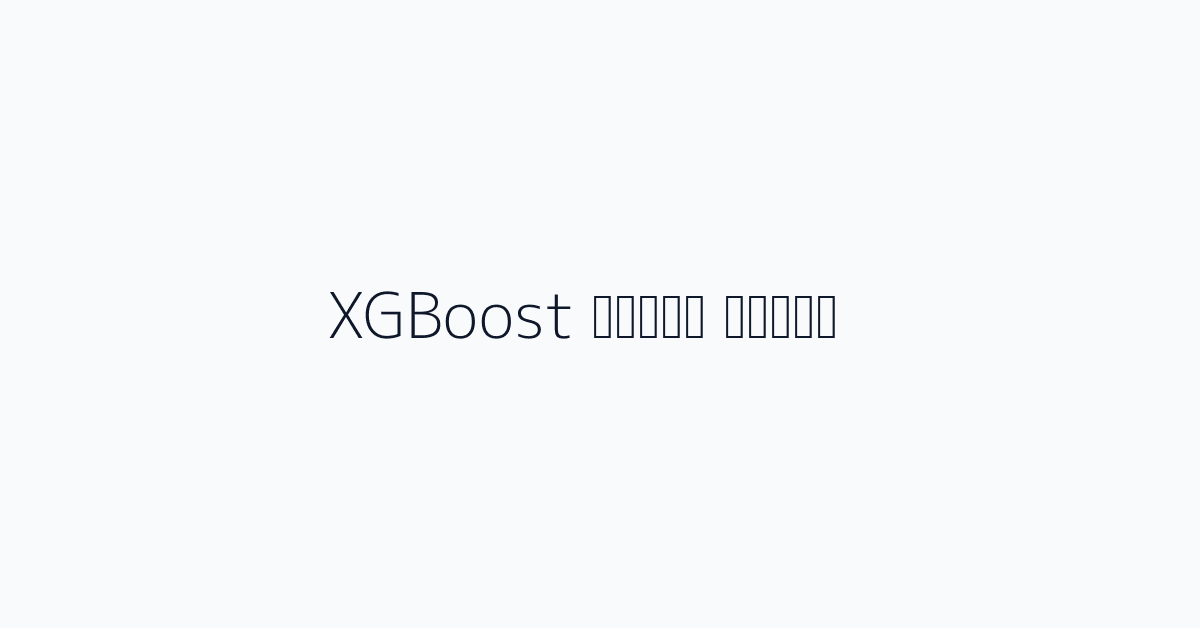
from xgboost import XGBClassifier
from sklearn.model_selection import TimeSeriesSplit
from sklearn.metrics import classification_report
def train_model(df: pd.DataFrame):
# فصل الميزات عن الهدف
exclude_cols = ['open', 'high', 'low', 'close', 'volume', 'target']
feature_cols = [c for c in df.columns if c not in exclude_cols]
X = df[feature_cols]
y = df['target']
# التحقق المتقاطع الزمني (لتجنب تسرب البيانات المستقبلية)
tscv = TimeSeriesSplit(n_splits=5)
model = XGBClassifier(
n_estimators=200,
max_depth=5,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
random_state=42
)
# استخدام آخر 20% كمجموعة اختبار
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
model.fit(X_train, y_train)
# تقييم الأداء
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
return model
# مثال للاستخدام
# model = train_model(df_with_features)دمج نموذج التعلم الآلي في روبوت التداول

def ml_trading_signal(model, current_features: pd.DataFrame) -> str:
"""إنشاء إشارة تداول باستخدام نموذج التعلم الآلي"""
proba = model.predict_proba(current_features)[0]
buy_prob = proba[1]
# احتمال الارتفاع
# إشارة قائمة على الاحتمالات (عند عدم اليقين، الانتظار)
if buy_prob > 0.65:
return 'BUY'
elif buy_prob < 0.35:
return 'SELL'
else:
return 'HOLD'البيانات هي كل شيء: كيفية جمع بيانات عالية الجودة

تعتمد أداء نموذج التعلم الآلي بنسبة تزيد عن 90% على جودة البيانات. استثمر وقتًا أكثر في البيانات مقارنة بالنموذج.
مصادر البيانات المجانية

- واجهة برمجة التطبيقات Binance: توفر بيانات OHLCV مجانية من دقيقة إلى شهر لسنوات عديدة
- CryptoCompare: بيانات عن القيمة السوقية، بيانات السلسلة
- Alternative.me: مؤشر الخوف والطمع (Fear & Greed Index)
- CoinGlass: بيانات التصفية، الفائدة المفتوحة
مصادر البيانات المدفوعة (متقدمة)
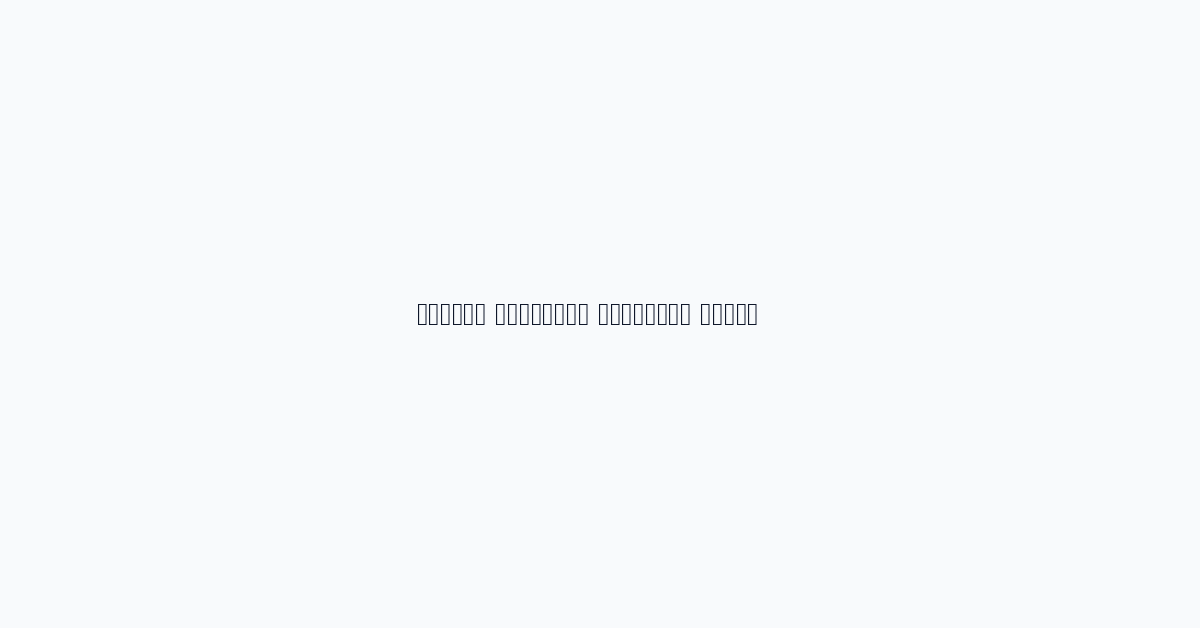
- Glassnode: بيانات تحليل السلسلة (29 دولارًا شهريًا)
- Kaiko: بيانات دقيقة عالية الجودة (للاستخدام المؤسسي)
- Santiment: مزيج من مشاعر وسائل التواصل الاجتماعي + بيانات السلسلة
تكوين خط أنابيب البيانات

import ccxt
import pandas as pd
from datetime import datetime, timedelta
def fetch_historical_data(symbol: str, timeframe: str, days: int) -> pd.DataFrame:
"""جمع البيانات التاريخية من Bithumb"""
exchange = ccxt.bithumb()
since = exchange.parse8601(
(datetime.now() - timedelta(days=days)).strftime('%Y-%m-%dT%H:%M:%S')
)
all_candles = []
while since < exchange.milliseconds():
candles = exchange.fetch_ohlcv(symbol, timeframe, since=since, limit=200)
if not candles:
break
all_candles.extend(candles)
since = candles[-1][0] + 1
df = pd.DataFrame(all_candles, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
return df🔧 أدوات مجانية مرتبطة
الخطوة التالية
تابع من هذا الدليل
ذو صلة
دليل يونيو 2026 لمقارنة إعادة تمويل الرهن العقاري في أمريكا عبر APR والنقاط والت...
ماليةمقارنة تأمين السيارات 2026 قبل تجديد الوثيقةدليل عملي حول مقارنة تأمين السيارات 2026 قبل تجديد الوثيقة مع نقاط فحص أساسية وم...
ماليةالدليل العملي لحساب ضريبة التملك: 500M، 1B، 1500M KRWPractical guide to الدليل العملي لحساب ضريبة التملك: 500M، 1B، 1500M KRW, with a...
ماليةBitcoin Halving 2028: Historical Patterns and Scenario Checklist (AR draft)دليل عملي حول Bitcoin Halving 2028: Historical Patterns and Scenario Checklist (...